今天来聊聊 Java 集合框架中最常用也是面试中最常见的 HashMap,我们一起来看看关于 HashMap 的八股文到底能整出些什么花头来。
1. 开篇词
今天来聊聊 Java 集合框架中最常用也是面试中最常见的 HashMap,我们一起来看看关于 HashMap 的八股文到底能整出些什么花头来。
2. 先来简单介绍一下 HashMap
这个问题可以先简单讲讲 HashMap 的基本特性,然后再延伸到底层数据结构、哈希算法、寻址算法、如何解决哈希冲突、线程安全问题、死循环问题、加载因子以及扩容机制等。
HashMap 是一个无序的 key-value 容器,它键和值都允许设置为 null,但是它是线程不安全的。同时在默认情况下如果 HashMap 元素超过指定容量的 0.75 时会扩容为原来的2倍。
2.1 详细说说 HashMap 的底层数据结构
在 JDK1.7 以前 HashMap 底层是数组和链表实现的,后来为了防止同一个数组下标中的链表长度过长导致查询效率降低的情况,从 JDK1.8 开始在 HashMap 容量大于64且链表长度大于8时会将链表转化为红黑树,即由数组、链表和红黑树实现。
在 JDK1.8 中 HashMap 的元素都以一个 Node 节点的形式存放在数组中,源码中 HashMap 的关键属性如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// ...
}
hash属性是键的哈希值,key属性存放的是键,value属性存放的是值。
hash 属性是键的哈希值,key 属性存放的是键,value 属性存放的是值。
还有一个next属性,就是当两个key的哈希值相同时,这两个元素会被放在数组的同一个下标位置中,通过next属性指定一下个Node对象,从而会形成一个链表。
如果使用图片的形式来描述 HashMap 的内部结构,一个包含四个键值对的 HashMap 可能是像下图这样的:

2.2 哈希值是如何计算的
当一个键值对被放入 HashMap 时,会通过 HashMap#hash(Object key) 方法来计算该键的哈希值,将哈希值作为它存放在 HashMap 数组中的索引下标值,hash 方法的源码如下所示。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
由此可见:
假如键为null的元素,它会被放在HashMap数组下标为0的位置。
当键不为null时,有hash值有如下的计算规则:
- h 被赋值为键的哈希值
- 进行无符号右移16位( h »> 16,右移后高位补0) 的运算
- 将上述两步的结果进行 ^ 异或运算(当两者不同时结果为1,相同时结果为0)
这种哈希算法的目的是让哈希值的高低16位都参与运算,最终目的还是为了充分散列,减少哈希碰撞。
下面就基于一个示例来计算哈希值,假设 h=15,我们来计算一下 HashMap 的哈希算法的结果。
先把15转化为二进制,也就是 0000 1111。然后对哈希值进行无符号右移16位的运算,其实就是在15的32位二进制中取高半区,也就是 0000 0000 0000 0000,最后对这两者做异或运算。
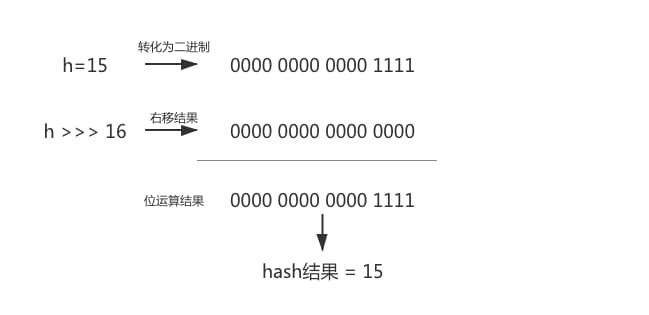
所以最终 h=15 的键值对将被存放在 HashMap 数组下标为15的位置。
2.3 介绍一下 HashMap 的寻址算法
所谓的寻址算法就是根据键的哈希值对数组长度取模,定位到数组的索引位置。在 JDK1.8 中,HashMap 的寻址算法是:
(n - 1) & hash
至于说为什么使用与运算(都为1时才为1),有两点原因:
- 首先自然是 (n - 1) & hash 结果与 hash 对 n 取模是一样的
- 对计算机而言,与运算性能比取模高很多
当然,使用这种寻址算法还有一个前提,那就是数组长度需要保证是2的n次幂。
2.4 HashMap 如何解决哈希碰撞
HashMap 的底层数据结构首先是一个 Node 类型的数组,一个 Node 节点存放在数组中的位置(即数组下标)是由该 Node 节点 key 属性的哈希值(也就是 hash 属性)确定的,但是这就可能产生一种特殊情况——不同 Node 节点的哈希值相同。
如果存在两个 Node 节点的 hash 属性相同,那么它们都会存放在数组下标为 hash 的位置,同时会通过 Node 节点的 next 属性将这两个节点连接在一起,形成一个链表,这就解决了哈希冲突的问题。
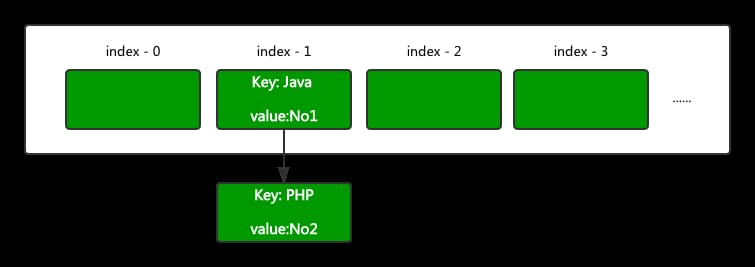
举个例子,当我在 Map 中添加一个键为 Java 值为 No1 的元素时,Java 字符串会通过 hash 方法来计算哈希值。假设 Java 字符串的哈希值为1,那么此时 HashMap 的结构就是下面这样。

假设这时再放入一个键为 PHP 值为 No2 的元素,刚好很不巧假设 PHP 作为键的哈希值结果也是1,那么这个 Node 节点也会放在数组下标为1的位置上,同时与 Java 键形成一个链表,如下图所示。
JDK1.7中是头插法,会引起死循环,在JDK1.8中改为使用尾插法。
但是如果发生大量哈希值相同的特殊情况,导致链表很长,就会严重影响 HashMap 的性能,因为链表的查询效率需要遍历所有 Node 节点。
于是在 JDK1.8 引入了红黑树,当链表的长度大于8且HashMap的容量大于64的时候,就会将链表转化为红黑树,链表树化的源码如下:
// JDK1.8 HashMap#putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// 省略
// binCount 是该链表的长度计数器,当链表长度大于等于8时,执行树化方法
// TREEIFY_THRESHOLD = 8
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
// 省略
}
// HashMap#treeifyBin
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// MIN_TREEIFY_CAPACITY=64
// 若 HashMap 的大小小于64,仅扩容,不会转化为红黑树
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 代码省略...
}
}
2.5 为什么HashMap是线程不安全的
说到这个问题,CSDN 上有一篇比较全面的回答,小生看完之后直呼可以,推荐大家也可以看一看:JDK1.7和JDK1.8中HashMap为什么是线程不安全的?
在这里还是总结一下:
- 在 JDK1.7 中,并发执行扩容操作时会造成环形链和数据丢失的情况
- 在 JDK1.8 中,并发执行put操作时会发生数据覆盖的情况
2.6 HashMap 的加载因子为什么是 0.75
HashMap 在进行扩容的时候有一定的条件,就是元素超过容量的0.75。这个0.75就是 HashMap 的加载因子,它是用来进行扩容判断的。
HashMap中加载因子为0.75,是考虑到了性能和容量的平衡。
由加载因子的定义,可以知道它的取值范围是(0, 1]。
- 如果加载因子过小,那么扩容门槛低,扩容频繁,这虽然能使元素存储得更稀疏,有效避免了哈希冲突发生,同时操作性能较高,但是会占用更多的空间。
- 如果加载因子过大,那么扩容门槛高,扩容不频繁,虽然占用的空间降低了,但是这会导致元素存储密集,发生哈希冲突的概率大大提高,从而导致存储元素的数据结构更加复杂(用于解决哈希冲突),最终导致操作性能降低。
- 还有一个因素是为了提升扩容效率。因为 HashMap 的容量(size 属性,构造函数中的 initialCapacity 变量)有一个要求:一定是2的幂次方。所以加载因子选择了 0.75 可以保证它与容量的乘积为整数。
// 构造函数
public HashMap(int initialCapacity, float loadFactor) {
// ……
this.loadFactor = loadFactor;// 加载因子
// 保证
this.threshold = tableSizeFor(initialCapacity);
}
/**
* 返回2的幂
* Returns a power of two size for the given target capacity.
* MAXIMUM_CAPACITY = 1 << 30
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
2.7 HashMap容量为什么规定为2的n次幂
- 原因一:与运算高效
与运算 &,基于二进制数值,同时为1结果为1,否则就是0。如1&1=1,1&0=0,0&0=0。使用与运算的原因就是对于计算机来说,与运算十分高效。
- 原因二:有利于元素充分散列,减少 Hash 碰撞
在给 HashMap 添加元素的 putVal 函数中,有这样一段代码:
// n为容量,hash为该元素的hash值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
它会在添加元素时,通过 i = (n - 1) & hash 计算该元素在HashMap中的位置。
当 HashMap 的容量为 2 的 n 次幂时,他的二进制值是100000……(n个0),所以 n-1 的值就是 011111……(n个1),这样的话 (n - 1) & hash 的值才能够充分散列。
举个例子,假设容量为16,现在有哈希值为 1111,1110,1011,1001 四种将被添加,它们与 n-1(15的二进制=01111)的哈希值分别为 1111、1110、1110、1011,都不相同。
而假设容量不为2的n次幂,假设为10,那么它与上述四个哈希值进行与运算的结果分别是:0101、0100、0001、0001。
可以看到后两个值发生了碰撞,从中可以看出,非2的n次幂会加大哈希碰撞的概率。所以 HashMap 的容量设置为2的n次幂有利于元素的充分散列。
3. 简单介绍一下红黑树
红黑树是一棵特殊的二叉搜索树,除了根节点外,每个非根节点有且只有一个父节点,对于一个节点来说,它的左子树上所有节点的值都小于等于根节点的值,它的右子树上的值都大于等于根节点的值,同时从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
基于红黑树这样的结构特性,它的时间复杂度是O(logn),所以会比链表的O(N)快,这也就是JDK1.8引入红黑树的原因。
在此附上一篇博文,描述了红黑树维护的详情:聊一聊红黑树的左旋和右旋(结合JAVA中TreeMap红黑树实现),这里面那张动图可以说是十分形象了。
4. HashMap 死循环是怎么回事
上文在说到为什么HashMap是线程不安全的的时候提到过在JDK1.7中由于哈希碰撞,在同一个数组下标中进行链表元素的新增时是用头插法,会导致死循环,而在JDK1.8中改为使用尾插法,避免了死循环的情况的发生。
在此贴出网上比较详细的解释分析博客与视频:
5. 小结
回顾一下本文提到的 HashMap 八股文:
- HashMap的底层数据结构是怎么样的?
- 哈希值是如何计算的?简单说下哈希算法
- 介绍一下 HashMap 的寻址算法?为什么用与运算而非取模?
- 哈希碰撞是什么?如何解决?
- 为什么 HashMap 是线程不安全的?
- HashMap 的加载因子为什么是0.75?
- HashMap 容量为什么规定为2的n次幂?
- 简单说下红黑树的特性
- HashMap 死循环是怎么回事?
在阅读完本文之后,你对上文这些问题是否已经了然于胸了呢?
6. 参考资料
最后,本文收录于个人语雀知识库: 我所理解的后端技术,欢迎来访。