在分布式系统中,分布式锁是一块重要的内容,如果在简历上写到自己有分布式锁的实践经验,或许这会是让面试官眼前一亮的地方。本周的议题就是分布式锁,我将从以下几个方面来展开讨论:
- 为什么需要分布式锁?
- 如何实现一个分布式锁?
- 分布式锁需要考虑哪些可能出现问题?
1. 为什么需要分布式锁?
分布式锁,我们把它拆开来就是”分布式“与”锁“,即分布式系统中的锁。在单体应用中我们通过锁解决的是控制共享资源访问的问题,而分布式锁,就是解决了分布式系统中控制共享资源访问的问题。
与单体应用不同的是,分布式系统中竞争共享资源的最小粒度从线程升级成了进程,也可以说就是微服务。
可以想象这样一种场景:在生产环境中有A、B两台实例,同时在跑一个生成单个订单报告的定时任务,为了防止报告重复生成,浪费系统资源,我们就可以使用分布式锁,在生成单个订单报告时把该订单锁住,这样就保证了单个订单的报告只生成一次。
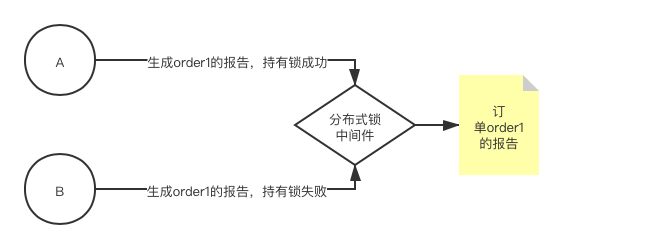
这种场景是读业务,或者也可以概括为幂等业务,使用分布式锁的原因是可以避免业务重复执行,提高了业务的效率,同时也节省了系统资源。
还有一种场景是写业务,这里特指非幂等业务,比如说:在一个订单下单成功后,只允许一种付款渠道的付款操作成功执行。
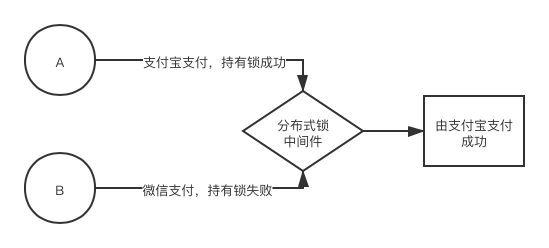
这里使用分布式锁的原因就是为了避免重复操作导致的数据不一致,像上面的例子中就是为了避免多次支付。
2. 分布式锁可能出现的问题
上面说了分布式环境中需要分布式锁的原因,接下来总结一下网上以及笔者本人碰到过的一些分布式锁可能遇到的问题,这对于后续优化分布式锁是很有用的。
2.1 分布式死锁
分布式死锁问题严格来说不能称为”死锁“,因为它不满足死锁的互相持有并等待条件,它只是一个”死去“的分布式锁。
常见场景:ServerA 加锁成功后宕机或s发生异常,未能将分布式锁解锁,导致后续客户端加锁失败。
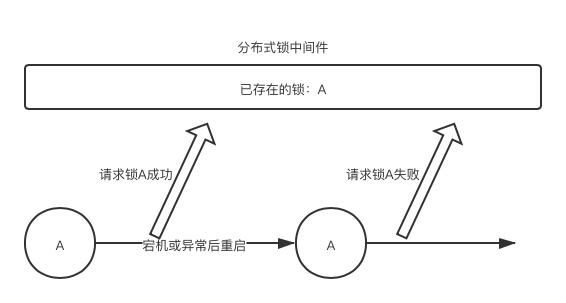
解决方案:加分布式锁时,设置过期时间,即到期自动解锁机制。
2.2 自动解锁问题
引入到期自动解锁机制,虽然解决了分布式死锁问题,但却带来了新的问题,那就是自动解锁问题。
常见场景:ServerA 持有分布式锁后,由于事务处理时长大于其设置的过期时间,分布式锁自动释放,导致业务执行完成后想要解锁却无锁可解。
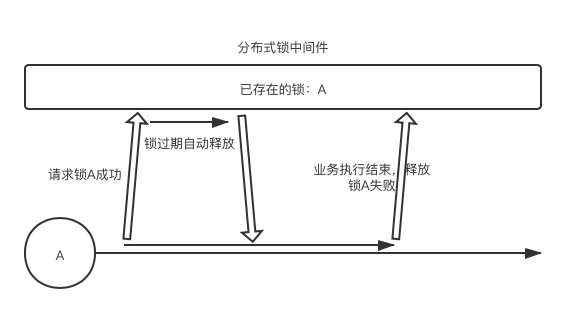
解决方案:另起线程对分布式锁进行自动续期,如 redission 的 watch dog 就提供了自动续期功能:每隔10秒检查一次,若客户端还持有锁则自动续期。
2.3 区分不同客户端的操作
在客户端多实例的场景中,一个分布式锁中还需要具备的一个功能就是区分来自不同客户端的操作。简单来说,就是 ServerA 加的锁除了自动解锁之外必须由它自己解锁。
常见场景:ServerA 持有分布式锁,由于在 Redis 中分布式锁的 key 一致,被 ServerB 的解锁命令解锁,导致 ServerA 完成业务后想要解锁却无锁可解。
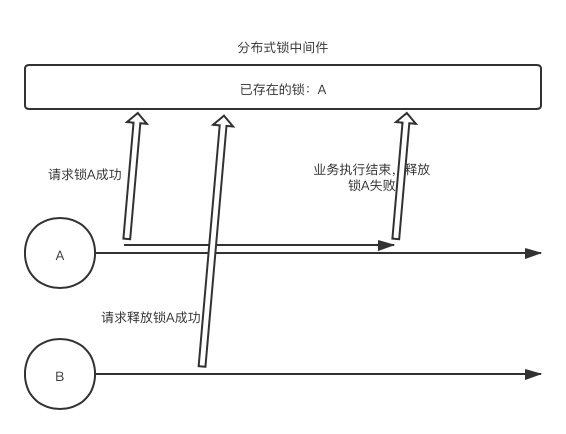
解决方案:在加锁时,加上客户端标识,如 key (减库存操作:商品编号),value (A:过期时间时间戳),在解锁操作中对 value 进行逻辑判断,保证主动解锁只能由 ServerA 完成。
2.4 可重入锁
所谓的可重入锁就是当客户端获取锁时,在业务中再次获取锁不会发生死锁的情况。
常见场景:ServerA 加锁成功后,业务内需要再次加锁。
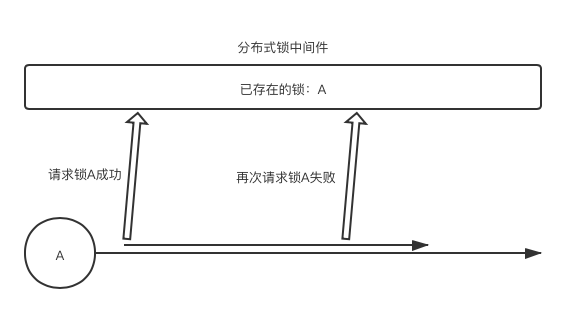
解决方案:将分布式锁改为可重入锁,加锁时进行判断,若 key 及客户端标识相同且锁未过期,将锁的过期时间延长。
3. 如何实现一个分布式锁?
上面说了分布式环境中需要分布式锁的原因以及分布式锁可能出现的问题,接下来聊聊如何实现一个分布式锁。
我认为实现一个分布式锁的思路就是借助一个各个实例都能够访问到的“中间件”来实现,并且这个中间件能够具有一些属性来保证分布式锁的排它性、容错性、以及能够有效避免死锁。
通常实现分布式锁的方式有三种:数据库、Zookeeper、Redis,下面就分别来介绍。
首先申明应用场景:在一个订单下单成功后,只允许一种付款渠道的付款操作成功执行。同时我们假设以上三种中间件实现方式都是单实例的,非集群的。
3.1 基于MySQL实现分布式锁
第一种方案是通过数据库来实现分布式锁,以 MySQL 为例,建立分布式锁表,以订单编号建立唯一索引,保证只有一条记录能够被插入成功。
CREATE TABLE `distributed_lock` (
`id` int(0) NOT NULL,
`order_no` varchar(36) DEFAULT NULL COMMENT '订单编号',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `idx_order_no`(`order_no`) USING BTREE
) ENGINE = InnoDB;
客户端竞争分布式的流程伪代码是这样的:
public Integer lock(String orderNo) {
// 查询该orderNo的分布式锁记录是否存在
if(queryLockByOrderNo(orderNo)) {
retrun null;
}
try {
// 插入记录成功,即竞争锁,返回锁主键id
return insertDistributedLock(orderNo);;
} catch (Exception e) {
// 插入失败,竞争锁失败
return null;
}
}
- 首先根据 orderNo 查询该订单的分布式锁是否存在,若已存在,代表分布式锁已被持有;若不存在,进入加锁逻辑
- 需要注意的是,这里的查询需要使用当前读,以此来防止幻读,如 **select * from distributed_lock where order_no=’xxx’ for update; **
- 加锁逻辑就是往 distributed_lock 表中插入一条数据,成功则返回锁记录的主键 ID
上面这段伪代码展示了使用数据库来实现分布式锁的主要思路,当然这段加锁逻辑还是存在一些其他问题的,按照之前所讨论的分布式锁可能出现的问题来说,比如:
- 支付业务如果报错了,如何保证锁能正常释放?(分布式死锁问题)
- 如何保证”我“加的锁只能由”我“释放?(如何区分不同客户端操作)
- 如何实现可重入锁?
除此之外,通过数据库来实现分布式锁主要的瓶颈还是性能问题:
- 由于查询时使用当前读,会加上排它锁,既然加了锁当然会影响到性能,造成阻塞,甚至可能发生死锁。
- 假设两个请求同时要加分布式锁,当一个请求在查询语句处执行成功后,另一个请求必然会被阻塞,这样就造成了响应阻塞,如果这时候请求量一大,必然会影响其他业务的正常执行。
- 当 distributed_lock 表数据量达到一定程度时,会影响查询性能,需要另外的逻辑来将无效的锁删除。
基于上面的原因,一般不使用数据库来实现一个分布式锁。
3.2 基于Zookeeper实现分布式锁
略。
是的,你没有看错,由于笔者对 Zookeeper 知之甚少,就不在此贻笑大方了,待日后完善了 Zookeeper 方面的技能树后,再来补全,在这里就做一个 TODO 的标记。
可以通过这篇文章 基于Zookeeper实现分布式锁 初步了解它的实现原理。
3.3 基于Redis实现分布式锁
第三种方案是通过 Redis 实现分布式锁,这是我在项目中实现分布式锁的方式,也几乎是目前最常用的分布式锁实现方案了。
注:我通过 Spring 自带的工具类 org.springframework.data.redis.core.RedisTemplate 来实现分布式锁,spring-boot-starter-data-redis 依赖的版本号为2.3.5.RELEASE。
3.3.1 Version1(基础分布式锁)
在 Redis 中有一个命令是 setnx,它代表若键不存在则设置成功,这个特性可以用来实现分布式锁的排它性,而在 RedisTemplate 提供的方法中,有一个名叫 setIfAbsent(K key, V value) 的方法底层就是使用了 setnx 命令,可以通过该方法实现一个最基础的分布式锁:
@Resource
private RedisTemplate<String, String> redisTemplate;
public boolean lock(String key, String value) {
if(redisTemplate.opsForValue().setIfAbsent(key, value)) {
return true;
}
return false;
}
public boolean unlock(String redisKey) {
// 若 redis 中不存在键则解锁失败
String redisValue = redisTemplate.opsForValue().get(redisKey);
if (StringUtils.isEmpty(redisValue)) {
return false;
}
// 若 Redis 中存在键,将键删除成功则解锁成功
if (redisTemplate.opsForValue().getOperations().delete(redisKey)) {
return true;
}
return false;
}
3.3.2 Version2(解决分布式死锁)
基于 Redis 实现的基础版分布式锁有一个最常见的问题,那就是分布式死锁问题:如果客户端持有一个分布式锁,却又因为异常或宕机未主动将锁释放,那么将导致这把锁会一直存在于 Redis 中,后续会该键的加锁操作都会失败。
在前文中也讨论过,分布式死锁的解决方案是把锁加上一个过期时间。
RedisTemplate 提供了一个带过期时间的重载方法 setIfAbsent(K key, V value, long timeout, TimeUnit unit),可以用来解决分布式死锁问题。
@Resource
private RedisTemplate<String, String> redisTemplate;
public boolean lock(String key, String value, long timeout, TimeUnit unit) {
if(redisTemplate.opsForValue().setIfAbsent(key, value, timeout, unit)) {
return true;
}
return false;
}
3.3.3 Version3(解决自动解锁)
通过给分布式锁加上过期时间之后,就可以避免因程序异常或宕机导致的死锁问题了,但是这样也会带来新的问题:自动解锁问题。
在前文中也讨论过,自动解锁问题可以通过给分布式锁添加自动续期功能来解决,如 Redission 的 watch dog 就可以实现对键进行自动续期,它会每隔10秒对键发起一次检查,若依旧被客户端持有,就延长它的过期时间。
但是,这样也会引入新的问题,那就是如何处理过期时间在10秒以内的分布式锁自动解锁问题呢?这个问题后文在讨论,Anyway,这里先把自动解锁问题给解决了再说其他。
笔者没有使用 Redission 的经验,所以在此不班门弄斧,而对于自动解锁的问题,我觉得可以有下面的解决方案:
- 通过设置合适的过期时间:可以事先在开发环境进行多次测试,计算一个平均业务执行时间,并适当加长,以此来防止自动解锁问题。
- 在客户端维护一个持有分布式锁的容器,在每一个锁设置的过期时间的1/3处,通过另起线程的形式进行对分布式锁的续期操作。
- 这种做法是模仿 Redission 的实现方式,只不过是通过客户端自定义的代码来实现自动续期。
- 当然这种做法会有资源的消耗以及性能、并发上的问题,但这里只是提出一个方案。
3.3.4 Version4(区分不同客户端操作)
通过给分布式设置合适的过期时间或锁添加自动续期功能,解决了分布式锁自动解锁问题。但这还没完,还有其他问题尚未解决——那就是前文中也讨论过的如何区分不同客户端的操作,即“我”加的锁只能由我自己来进行主动解锁。
这个问题的解决方案就是在 Redis 的值中添加客户端标识,在解锁时进行逻辑判断即可。
// 该项可以作为配置项在 application 配置文件中设置
private final static String ServerSingle = "ServerA:";
public boolean lock(String key, String value, long timeout, TimeUnit unit) {
// value = ServerSingle + value
if(redisTemplate.opsForValue().setIfAbsent(key, ServerSingle + value, timeout, unit)) {
return true;
}
return false;
}
public boolean unlock(String redisKey) {
String redisValue = redisTemplate.opsForValue().get(redisKey);
// 若 redis 中不存在键,或者值不包含本客户端标志 则解锁失败
if (StringUtils.isEmpty(redisValue) || !redisValue.contains(ServerSingle)) {
return false;
}
// 删除键成功则解锁成功
if (redisTemplate.opsForValue().getOperations().delete(redisKey)) {
return true;
}
return false;
}
3.3.5 Version5(可重入锁)
接下来就是前文中列出的最后一个问题——可重入锁。所谓的可重入锁,指的是同一线程外层函数获得锁之后 ,内层函数仍然有获取该锁的代码,可再次获取锁,不会发生死锁的情况。
将分布式锁改造为可重入锁的代码如下:
// 该项可以作为配置项在 application 配置文件中设置
private final static String ServerSingle = "ServerA:";
public boolean lock(String key, String value, long timeout, TimeUnit unit) {
// value = ServerSingle + value
if(redisTemplate.opsForValue().setIfAbsent(key, ServerSingle + value, timeout, unit)) {
return true;
}
// 设置分布式锁失败,可能是锁已被其他客户端持有,或者本客户端持有
if(value==null || !value.contains(ServerSingle)) {
return false;
}
// 使用 setIfPresent 方法,避免锁过期
if(redisTemplate.opsForValue().setIfPresent(redisKey, ServerSingle + value, timeout, unit)) {
return true;
}
return false;
}
public boolean unlock(String redisKey) {
String redisValue = redisTemplate.opsForValue().get(redisKey);
// 若 redis 中不存在键,或者值不包含本客户端标志 则解锁失败
if (StringUtils.isEmpty(redisValue) || !redisValue.contains(ServerSingle)) {
return false;
}
// 删除键成功则解锁成功
if (redisTemplate.opsForValue().getOperations().delete(redisKey)) {
return true;
}
return false;
}
- 首先通过客户端标识防止了其他客户端操作
- 然后通过 setIfPresent 方法防止锁过期
这个版本的基于 Redis 实现的分布式锁可以算是最完整的版本了,基本解决了以上提出的所有问题。
关于分布式锁的讨论到这里就结束了,如果文中有什么不妥当的地方,万望各位看官指出,在此先谢过各位了。
4. 温故知新
- 为什么需要分布式锁?
- 分布式锁可能出现的问题?
- 如何实现一个分布式锁?
最后,本文收录于个人语雀知识库: 我所理解的后端技术,欢迎来访。
文档信息
- 本文作者:Planeswalker23
- 本文链接:https://planeswalker23.github.io/2020/11/24/%E6%88%91%E6%89%80%E7%90%86%E8%A7%A3%E7%9A%84%E5%85%B6%E4%BB%96%E9%97%AE%E9%A2%98-%E7%AC%AC11%E7%AF%87-%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E9%9C%80%E8%A6%81%E8%A7%A3%E5%86%B3%E5%93%AA%E4%BA%9B%E9%97%AE%E9%A2%98/
- 版权声明:本作品系原创,作者保留所有权利,未经作者允许,禁止转载和演绎。